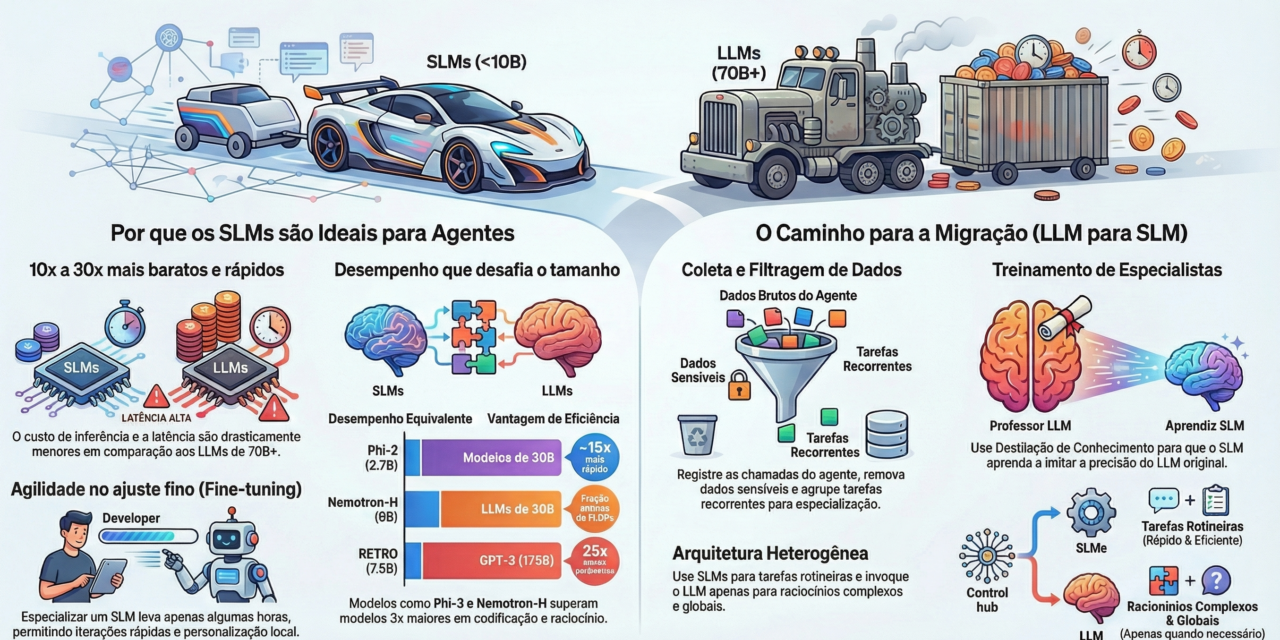
Estamos vivendo um paradoxo na inteligência artificial: empresas estão usando “canhões para matar mosquitos”. Modelos gigantes estão sendo aplicados em tarefas simples, repetitivas e previsíveis — o que gera custo alto, latência desnecessária e complexidade operacional. Isso não escala bem. E pior: cria dependência tecnológica sem ganho proporcional de valor.
O movimento mais relevante hoje não é sobre modelos maiores, mas sobre modelos mais eficientes. Os chamados Small Language Models (SLMs) estão entregando resultados comparáveis — e em alguns casos superiores — em tarefas específicas, com uma fração do custo. Para quem pensa em negócio, isso muda completamente o jogo: menos gasto com infraestrutura, mais velocidade de execução e maior previsibilidade operacional.
Do ponto de vista arquitetural, o futuro não é monolítico — é modular. Em vez de um único modelo tentando resolver tudo, passamos a orquestrar múltiplos modelos especializados, cada um responsável por uma função clara. Isso reduz desperdício, melhora performance e permite algo crítico: controle. Controle de custo, de dados e da evolução da solução.
No fim, isso não é uma discussão técnica — é uma decisão estratégica. Quem continuar apostando apenas em modelos grandes vai pagar mais caro por menos eficiência. Quem entender a lógica de especialização e modularidade vai construir soluções mais rápidas, mais baratas e mais escaláveis. A pergunta não é se isso vai acontecer — é quando você vai ajustar sua arquitetura para essa realidade.
por Walker de Alencar



{kind=link}